El viernes 5 de agosto me voy con toda la familia a un pueblo de Extremadura cerca de la frontera con Portugal (Valencia de Alcántara) a visitar a unos amigos. Regresábamos el martes 9 a la tarde, ¿qué podía pasar en Menéame que no se pudiese solucionar con una navegador y la consola web de AWS si nunca habíamos tenido problemas graves? Si necesitaba algo más, podía instalar las herramientas de AWS en otro ordenador y solucionarlo en pocos minutos. Así que por primera vez viajo sin mi portátil, sólo mi tablet Android con conexión 3G Vodafone (además de mi teléfono también con 3G).
Pues ocurrió el desastre en Amazon, les falló todo lo que podía fallar, todos nuestros planes de contingencia no podía aplicarse (salvo el “rehacer desde cero” con los bakups) y yo sin mi portátil y con el 3G completamente inestable, prácticamente como si no tuviese conexión. Si no hubiese sido así Menéame no habría estado “off line” tanto tiempo, quizás sólo unas pocas horas. Fue una pesadilla.
Amazon tuvo varios fallos: primero el corte completo de la conectividad a todas las instancias, luego la desincronización del API de gestión, luego los EBS que quedaron totalmente inaccesibles y bloqueando la gestión de las instancias que los usaban, y para rematar un fallo en el software de creación de los “snapshots” (backups por bloques en S3) que borraba datos de algunos bloques (lo descubrieron durante la crisis, y nos afectó a nosotros).
Nota: es un relato rápido, ya corregiré erratas, ahora me voy a duchar, que la última vez fue en Valencia de Alcántara 😉
Arquitectura y planes de contingencia de Menéame
- Los servidores webs de Menéame se crean y destruyen automáticamente, monitorizados por Amazon CloudWatch y el LoadBalancer. Además desarrollé otro programa que se asegura que todos estén en funcionamiento correcto, caso contrario los destruye y obliga a la creación de nuevas instancias, así no tengo que preocuparme siquiera de mirar el estado, se “auto reparan” vía dos sistemas de control independientes. Pero estos no fallaron en ningún momento.
- Además tenemos dos servidores críticos para los servicios: el de base de datos (awsb) y el de NFS+autentificación+réplica base de datos (aws0). awsb es el máster de la base de datos, el más crítico y costoso de levantar, pero tiene una réplica en tiempo real en aws0. Cambiar para que aws0 se convierta en máster (failback) es sólo cuestión de cambiar una línea en un fichero de configuración local.php (y otra más para los programas “offline” en Python y Perl).
- Se hacen backups diarios de las base de datos que se guardan en otro EBS independiente, y que sincroniza automáticamente los ficheros en S3.
- Las imágenes y avatares se guardan en un EBS independiente, con copia automática a S3. En caso de fallo del EBS sólo hace falta crear uno nuevo, las imágenes se bajan automáticamente bajo demanda.
- En caso de fallo del EBS con el código fuente y las utilidades necesarias tienen backup diario en otro EBS, que sincroniza automáticamente con S3.
- Además teníamos (sí, pretérito, porque también se jodieron con el fallo de Amazon, otro bug que descubrieron ahora) imágenes en “snapshots” de cada una de las dos máquinas. Si una se moría y perdía todos los datos súbitamente, era cuestión de arrancar otra desde el snapshot, recuperar los datos de backups (desde otro EBS o S3) y asignarle la “IP elástica” para que vuelva a la normalidad.
- Con todos estas precauciones y planes de contingencias, el tiempo de recuperación era desde unos pocos minutos hasta un máximo de 120 minutos, que es lo que se tarda en recuperar completamente la base de datos desde un el “dump” diario (la importación de datos tarda exactamente 110 minutos).
Para hacer cualquiera de las operaciones previas, basta la consola web y comandos básicos de la consola de GNU/Linux, como hacer un tar, o importar los datos a mysql desde un dump de backup. Es decir, nada que no pudiese cualquier otro sysadmin de Menéame. El tiempo estimado en el peor de los casos era de 120 minutos, supongamos que tome el doble. Cuatro horas en cálculos pesimistas para volver online ante un evento de bajísima probabilidad me parecía más que razonable para un sistema que no es crítico para nadie, ni cobra a sus clientes, ni tenemos contratos de servicios con terceros.
Pero lo que no se nos había ocurrido era que fallasen todos los EBS al mismo tiempo, y que los “snapshots” también estuviesen corruptos. No sé si es estupidez o no, pero prometo que no se me pasó por la cabeza, mucho menos que ocurriese mientras yo estuviese en un pueblo casi aislado, sin casi conexión a Internet, ni mi portátil con todas las herramientas. Lo pasé fatal.
La crisis
El domingo a las 19:40 se desconectan todas las instancias, el Menéame es inaccesible por web, tampoco podíamos acceder a las instancias. Aproximadamente a las 20 hs me avisan por SMS. Voy a verificar, no me puedo conectar (usando el ConnectBot de Android) a ninguna de las instancias, sin embargo en la consola web aparecían en estado normal. Abrimos un ticket de soporte web, pocos minutos después Amazon publica que tiene problemas de conectividad en una de sus regiones (i.e. un centro de datos), que es justamente la que estábamos usando. Nos responden que el problema es general y que están trabjando en ello. Me avisan además que hasta Paypal estaba caído. Es decir, una emergencia. Me quedo más tranquilo, ya lo solucionarán. Me voy a cenar con toda la familia, además ese noche era el festejo de la “Boda Regia”.
Durante toda la cena iba probando conectarme desde el móvil. Como a la 1 de la mañana, estando bebiendo unos gintonics en el castillo (@bufetameida y @pixspain en Twitter pueden ratificar lo que cuento, fueron testigos de primera mano) logro entrar por ssh a ambos servidores, aws0 y awsb. El segundo (el máster de la base de datos) estaba perfecto, la base de datos intacta, pero el kernel de aws0 daba errores graves de acceso a los EBS. Tampoco había conectividad entre ellos (ni con ping).
Volvemos a la casa del pueblo (de Carlos Almeida), me conecto con el tablet. La conexión variaba de GPRS a 3G y HDSPA cada pocos segundos, por lo que la conexión ssh era una pesadilla. Intento arreglarlo desmontando los EBS, pero el umount se quedaba bloqueado, es decir, el fallo era muy importante, no había “comunicación” con esos dispositivos.
Hago un reboot de aws0, el reboot se bloquea en mitad del proceso según se veía en la consola web de Amazon AWS. No importa, pienso, tenía un “snapshot” con su AMI correspondiente (para poder arrancar una instancia idéntica directamente) de hacía pocos meses (el 1 de marzo). Desde la consola web hago que arranque una nueva instancia, me da error del snapshot. ¡Mierda! lo que me faltaba, pensé, había hecho algo mal durante la creación del AMI. Al día siguiente nos avisarían que había sido otro problema:
Separately, and independent from the power issue in the affected availability zone, we’ve discovered an error in the EBS software that cleans up unused snapshots. During a recent run of this EBS software in the EU-West Region, one or more blocks in a number of EBS snapshots were incorrectly deleted. The root cause was a software error that caused the snapshot references to a subset of blocks to be missed during the reference counting process. This process compares the blocks scheduled for deletion to the blocks referenced in customer snapshots. As a result of the software error, the EBS snapshot management system in the EU-West Region incorrectly thought some of the blocks were no longer being used and deleted them. We’ve addressed the error in the EBS snapshot system to prevent it from recurring. We have now also disabled all of the snapshots that contain these missing blocks.
En pocas palabras, que los snapshots de los discos también estaban corruptos por un error en el software que los gestiona.

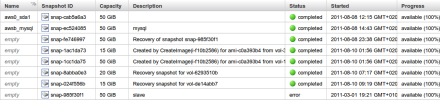
En la imagen se pueden ver los snapshots, el último (con el nombre “slave”) era el básico para levantar aws0. el Día 8 de agosto Amazon lo detectó como afectado por el error -y otro más- por lo que nos avisó crearía esas copas:
We are in the process of creating a copy of the affected snapshots where we’ve replaced the missing blocks with empty block(s). Customers can then create a volume from that copy and run a recovery tool on it (e.g. a file system recovery tool like fsck); in some cases this may restore normal volume operation. We will email affected customers as soon as we have the copy of their snapshot available. You can tell if you have a snapshot that has been affected via the DescribeSnapshots API or via the AWS Management Console. The status for the snapshot will be shown as “error.” Alternately, if you have any older or more recent snapshots that were unaffected, you will be able to create a volume from those snapshots without error. We apologize for any potential impact it might have on customers applications.
A la mierda, las cosas no podían ser peor (todavía no sabía los que acabo de contar sobre los errores de “snapshots”, ni los marcaba como erróneos en ese momento). En primer lugar, los EBS son dispositivos SAN con replicación automática, se supone (y así lo anuncian y venden) que fallan menos que los discos duros (pero se paga un precio además de las tarifas por operaciones, son muy lentos, no más de 25.000 bloques E/S por segundo, con una variabilidad enorme) y que al estar replicados los datos no se pierden. Pero esta vez no sólo que los datos eran inaccesibles, también bloqueaban a las instancias que lo usaban… y además se habían cargado las imágenes de backups.
Me voy a dormir, sin poder hacer nada (y con una conexión que se me cortaba cada minuto, en el mejor de los casos) más o menos a las 4:30 de la madrugada del lunes. Benjamí se queda trabajando y abriendo tickets de soporte, horas después me entero que le cortaron la luz en su pueblo a las 8 de la mañana y por varias horas. Sí, de verdad, no exagero.
Me levanto a las 10hs, me habían conseguido un portátil con Windows 7 (qué horror de usabilidad, al menos para este tipo de trabajo, no encontraba ni la consola), pongo el tablet en modo servidor de wifi. Me conecto, sigue todo igual que el día anterior, no habían solucionado nada. Incluso estaba peor, no podía acceder a aws0 ni awsb por ssh. Tenía varios mensajes de Carme contándome básicamente que no podía hacer nada, y que no había soluciones desde el soporte de Amazon.
Intento reiniciar aws0 por la consola, no hace nada. Entonces hago lo primero “peligroso”: detengo la instancia para intentar hacer otro snapshot completo y se ser posible volver a arrancarla. Se detiene correctamente, al indicar que la arranque otra vez, pasa a “pendientes” durante unos minutos y enseguida vuelve a ponerse en estado “stopped”.
Intento crear un AMI (la imagen de arranque), pero inmediatamente da “Internal Server error”. Me pongo a hacer snapshots independientes de cada uno de los tres EBS. Me funcionan los dos importantes, el del NFS y la copia de base de datos del slave (son los dos primeros backups que se observan en la imagen anterior) pero falla el del cache (el que se regenera automáticamente desde S3). Intento varias veces hacer un “detach” de ese EBS para ver si desbloqueaba la instancia, pero era imposible:

Así que estaba sin poder conectarme por ssh, ni quitarnos de encima el EBS que parecía ser el problema. Me estiraba de los pelos, no podía creer todo lo que estaba pasando.
Carlos Almeida y mi familia me piden me tranquilice, y casi me llevan a rastras a comer a Portugal (a Castelo de Vide) y con el roaming de datos deshabilitado. Volvemos como a las 19hs, la situación sigue igual, aws0 sigue muerta, sin poder arrancar, aunque puedo ya entrar a awsb. Tomo la decisión de recuperar la instancia desde los backups de EBS que tenía, creo una nueva instancia “limpia” de Ubuntu 10.4. Me bajo la clave privada RSA desde mi copia en Dropbox para poder hacer ssh con el usuario por defecto (ubuntu). No pude hacerla funcionar en putty. Me estaba frustrando, además con la conexión errante. Vi que había herramientas para convertirla a putty, hice lo que pude, pero fue infructuoso (quizás también la cabeza no me daba para mucho más).
Además el portátil con Windows 7 iba de esa forma, cada pocos minutos el puntero del ratón de ponía como una lupa, y no podía moverlo, sólo hacía zoom del escritorio o del navegador web. Tenía que reiniciarlo frecuentemente, y usando sólo el teclado. Lo importante en este punto es que si hubiese tenido mi portátil con las herramientas de AWS (lineas de comando en Java) habría podido recuperar Menéame en pocas horas (como así sucedió cuando regresé a casa). Todavía no termino de arrepentirme de no haberlo llevado.
Al día siguiente, martes 9, a las 18:10 hs teníamos el vuelo de Sevilla a Palma. El viaje en coche desde Valencia de Alcántara a Sevilla son cuatro horas, teníamos pensado salir a la mañana temprano para visitar Mérida, que está a medio camino. Cancelamos la visita así podía quedarme hasta más tarde, saldríamos a las 12hs directamente hacia Sevilla. Me quedé intentando recuperar aws0 y entrar a la instancia nueva hasta las 4 de la mañana. Me voy a dormir, que tenía que conducir. Me levanto a las 10hs, me conecto, sigue todo exactamente igual.
Teníamos varios avisos sobre los EBS y los snapshots, y que tomarían tiempo arreglarlos (entre 24 y 48 hs), que estaban modificando el API y la consola web para agregar el estado “error” en los EBS y snapshots -sí, no tenían previsto que fallasen de esta manera-. Además nos avisan que ya podríamos hacer el “detach” de las instancias, pero no funcionaba. Estaba igual que horas antes.
Salimos a las 12:15hs después de desayunar y tomar un café adicional (yo estaba hecho polvo). Mi mujer prepara unos bocatas así no teníamos que parar a comer. Llegamos a las 15:30 al aeropuerto de Sevilla, en los últimos 20 km no encontré ninguna gasolinera para llenar el depósito antes de devolver el coche. En el aeropuerto pregunto donde hay una, cojo la autovía hacia Sevilla Este, encuentro cerca la gasolinera, cargamos, a las 16hs estábamos en facturación. Veo que el vuelo que estaba programado a las 18:10 hs estaba retrasado, la hora prevista era a las 19:05. No me dejan facturar todavía porque estaban atendiendo sólo a los del vuelo a Lanzarote. Esperamos casi una hora, aprovecho para seguir intentando recuperar, sin éxito, aws0, voy a facturación, paso los DNI… y la chica me dice que nuestro vuelo era para el 9 de setiembre, no para agosto.

Me cago en la madre del primer homosapiens.
¿Qué otra cagada me faltaba por descubrir? Creo que mi mujer estaba por pedirme el divorcio en ese mismo momento. Yo sólo me reía. Nos vamos al mostrador de Air Europa, hay cuatro plazas disponibles. La chica me dice que le penalización por cambio de fechas y clase me sale más caro que comprar los cuatro billetes. Compro cuatro billetes nuevos (casi 300 euros, contando el descuento del 50% por residentes en Balears) y facturamos, allí nos dicen que el vuelo se retrasaría todavía una hora más. Me cago en la madre de neardentales y cromagnones, nunca iba a llegar a Palma.
Pasamos el control, nos instalamos en un bar a dar de comer a las niñas y tomarme un par de cafés. Recibo un correo del director de “social media” de Air Europa, se ofrecen de devolverme el importe de los billetes del 9 de setiembre, ya que recordaba que había tenido muchos problemas con la página web cuando los compré. Al menos una buena noticia, se lo digo a mi mujer, y al menos me puedo vengar de todos los insultos que me había dedicado (y supongo que se calló la mayoría) en los últimos minutos.
Pero la alegría duró poco, en las pantallas sale que la hora estimada de salida era a las 22 horas. A tomar por culo, el cuerpo ya no aguantaba. Me instalo en uno de esos bancos sexagonales del aeropuerto de Sevilla y duermo una siesta con mis piernas haciendo un ángulo perfecto de 120 grados con la espalda. Raquel me despierta poco antes de las 21hs porque los de Air Europa nos dieron unos tickets para que cenemos, vamos a cenar, luego al avión, subimos, nos explican el retraso se debe a que el avión venía de Lanzarote (sí, parece el mismo que embarcaba cuando llegamos al aeropuerto) y de tres secciones de controladores en Canarias sólo funcionaban dos por falta de personal. Y que para rematar ahora teníamos otro retraso por saturación al aeropuerto de Palma. Resultado, llegamos a las 0:45hs a casa.
Enciendo los ordenadores, la Nespresso, me tomo un par de cafés, un vaso de zumo de naranja y me siento a trabajar. La situación estaba exactamente igual que la noche anterior. Así que decido continuar trabajando en la instancia nueva que había creado estando en Valencia de Alcántara. A las 3 de la mañana Menéame ya funcionaba, a las 4:30 ya había recuperado todos los servicios, incluido la reconstrucción del slave de la base de datos desde el último backup que se había hecho el domingo a la madrugada (para estar más seguro no se perdían datos).
Lecciones aprendidas
Resumen breve: si hay probabilidades de morir por una vaca caída desde el cielo, mira para arriba.
Amazon vende a los EBS como sistemas muy fiables, tanto en su fallo anterior como en este, han sido el problema fundamental y que degeneró todo (de hecho las instancias webs, que sólo usan “almacenamiento volatil” no tuvieron ningún problema, sus datos estaba intactos).
Entiendo lo del rayo y que haya provocado un incendio. Lo que se me hace muy difícil de creer que ese corte haya forzado la resincronización de fase manual (ya en mi época de estudiante del grado de técnico electromecánico, hace 20 años, los sistemas de sincronización de fase eran automáticos), y que justamente haya afectado sólo a los sistemas más críticos (los EBS) y no a la alimentación de las instancias que seguían funcionando normalmente. También entiendo la enorme complejidad de los sistemas de Amazon, pero que además haya habido un bug que destruía los datos de los backups de los EBS me suena a la mayor de las putadas divinas después de la inundación en la que se salvó Noé y muchas parejas más. En el mejor de los casos parece que estamos pagando todos por la baja calidad de las subcontratas de Amazon, sobre todo teniendo en cuenta que los EBS fueron los que ocasionaron los problemas de la caída de hace unos meses en EEUU. Yo pensaba que no podía ocurrir dos veces lo mismo, y menos que fallen tantas cosas del mismo sistema: la alimentación, la sincronización, la pérdida de control desde el API, el bloqueo de instancias, los backups corruptos, la falta de automatización para recuperar la consistencia de datos (dijeron que estaban haciéndolo manualmente), y que haya afectado a todos los volúmenes de una región. ¿Todo por culpa de un rayo? Algo no cuadra.
Si la fiabilidad de EBS es la que hay ahora mismo, Amazon AWS no tiene sentido. Si tuviésemos que hacer un sistema completamente tolerante a todos estos fallos tendríamos que gastar más del doble para tener duplicado en tiempo real en otras regiones (y más complejidad si se hace el fallback automático o acceso distribuido), el tráfico entre regiones se paga, y la latencia es mayor.
Si hay que construir todo el sistema pensando en que los EBS pueden generar todos estos problemas, no sólo hay problemas de coste, también de administración de sistemas más complejos. Es decir, estamos pagando un sobreprecio importante (en dinero y rendimiento) por la supuesta fiabilidad de los EBS. Por menos de la mitad de precio se puede contruir la misma infraestructura en proveedores de hosting normales. En Menéame pagamos unos $1.300 euros mensuales de AWS, si tuviésemos que tener todo replicado y distribuido para sobrevivir a fallos generales de los EBS deberías gastar como mínimo el doble. Por mucho menos de ese precio podría tener una arquitectura igual de redundante y más eficiente (los discos duros más cutres son mucho más rápidos que un EBS, y por lo visto, mucho más fiables) en cualquier hosting tradicional.
Amazon debería re-estructurar y definir bien las condiciones de servicio de los EBS. Si estos problemas generalizados y “bloqueantes” pueden volver a ocurrir, acabaremos migrando a otro proveedor. No se puede vivir tranquilo con esta espada en la nuca por fallos catastróficos de los sistemas que te venden como “tolerantes a fallos y replicados” y sobre el que no pueden basar para construir los “planes de contingencia”. Teníamos varios de esos planes, todos fallaron. Nuestra estimación en el peor de los casos no llegaba a más de dos horas aún con la mayor catástrofe… si estoy disponible para hacer las tareas más complejas y que requieren mucha experiencia (es reconstruir la arquitectura casi desde cero, y con comandos del API no accesibles desde la consola web). Por lo tanto no disponible para la mayoría de las startups y empresas pequeñas, y mucho menos tener personal duplicado por si uno de ellos está desconectado en un pueblo de la Extremadura profunda cerca de la frontera con Portugal.
Si eres el único que puede recuperar un sistema cuando fallan todos los planes de contingencia anteriores, nunca viajes sin tu ordenador preparado, e incluso con 3G de varias empresas (que manda huevos, también tengo otro SIM de ONO que va por Movistar, y no lo había llevado). ¿Suena ridículo si estás pagando un sobreprecio para estar tranquilo? Pues sí, por eso acabo de ver y/o entender el modelo de negocio para solucionar emergencias de empresas que no pueden tener dos personas expertas en “la nube” para solucionar estas emergencias graves. Pero sigue siendo ridículo que haya que pagar otro sobreprecio para dar tolerancia a fallos a un sistema que te venden como tolerante a fallos.
Creo en “la nube”, y que es el futuro, pero Amazon ha fallado -dos veces- en asegurar el funcionamiento correcto del servicio crítico de un sistema que sirve de pilar a todo lo demás. No sé si tiene solución, ni cómo lo tomará Amazon. Pero si no hay aclaración de por qué no cumplen con sus condiciones de servicio y cómo será en el futuro, habrá que pensar en abandonarlo. Por ahora y mientras no haya esa aclaración técnica de cómo será en el futuro, no aconsejaría a ninguna startup que se mudara allí: te pueden arruinar las vacaciones, y afectar a la familia. Me ha pasado, en el peor momento posible
Sólo me queda pedir otra vez disculpas. Y prometo no volver a viajar sin mi portátil, al menos hasta que tengamos sistemas de fallback automáticos repartidos en al menos dos continentes y tres centros de datos.